MapReduce的Map Size Join以及Distributed Cache
本文共 471 字,大约阅读时间需要 1 分钟。
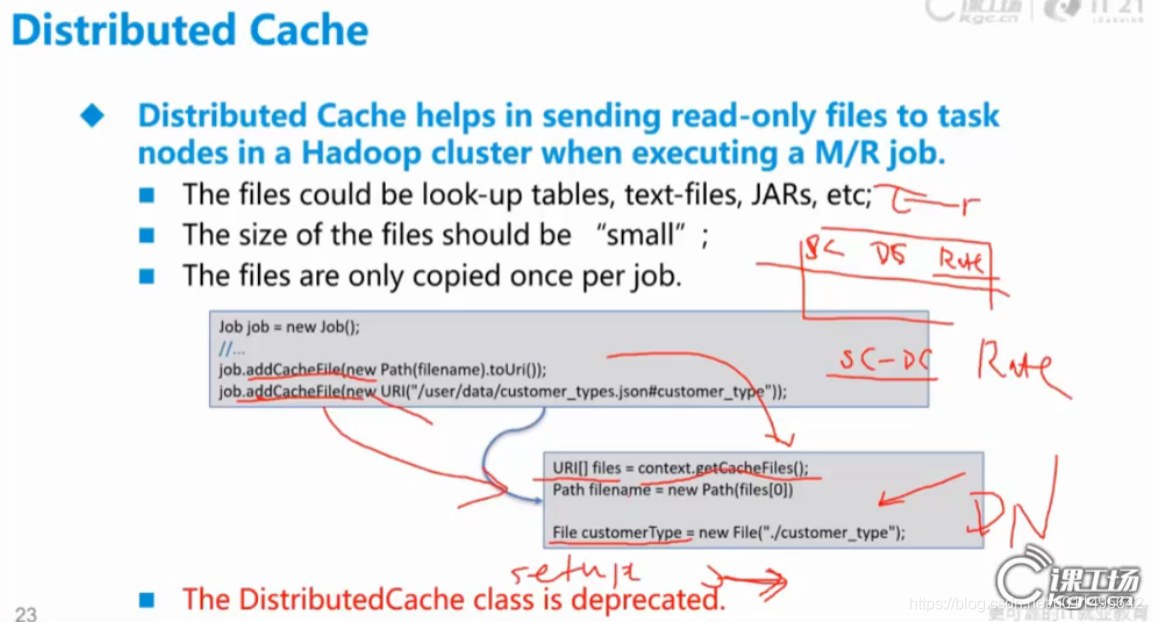
首先介绍Distributed Cache(分布式缓存),主要功能是把DataNode(客户端)一些小的文件送到DataNode上。
1. 通过job.addCacheFile(new Path(filename).toUri)
2.通过job.addCacheFile(new URI("xx/xxx/xxx/xx.json#customer_type"))
通过1和2来传过去(都是URI 就是方便你知道在客户端上这些文件的位置 )
如果知道文件路径的话,new File正好帮你创建一个。
如果不知道文件路径,可以通过context一口气获取所有缓存的文件,放到一个列表里,这样想拿谁都可以。
客户端某个文件的内容会被拿到DataNode,但不会修改这些内容,拿过来默认是和原来的文件一样的名字。#号可以重新起名。
Map-Side Join就是这样,在mapper的setup方法里,把这些小表拿过来
erFile:File = new File("./er.csv")
变成其他格式 比如Hashtable
然后和大表对照做Join

转载地址:http://fzvws.baihongyu.com/
你可能感兴趣的文章
java中ThreadLocal类的使用
查看>>
java中数组长度为零和为空的区别
查看>>
图解eclipse 查看原始类出现The jar file rt.jar has no source attachment
查看>>
JVM堆内存设置原理
查看>>
约瑟夫问题(java实现)
查看>>
Java 中int、String的类型转换
查看>>
java实现9大排序算法
查看>>
一句话总结java23种设计模式
查看>>
静态表查找
查看>>
乐观锁的一种实现方式——CAS
查看>>
JAVA线程间通信的几种方式
查看>>
IDEA中怎么新建package包,只有directory选项
查看>>
django admin 增加查看权限
查看>>
django后台加载从15秒优化到1秒的过程小记
查看>>
chrome不显示Django-suit左侧菜单栏
查看>>
Python区间库python-intervals
查看>>
django admin 登录用户名密码错误提示
查看>>
python3 AttributeError: 'function' object has no attribute 'func_name'
查看>>
解决ubuntu下修改my.cnf设置字符集导致mysql无法启动
查看>>
根据进程的PID查询对应端口号
查看>>